文 _ 茅奕(清华大学天文系)
近年来,尤其是ChatGPT和DeepSeek等大语言模型火爆出圈后,“人工智能+”成了最火最潮的关键词。在21厘米宇宙学领域,早在2017年就出现了第一篇应用机器学习的论文,随之而来,人工智能也在这个领域得到了广泛应用。笔者发表了近十篇有关将机器学习应用于21厘米宇宙学的学术论文,见证了这个领域蓬勃发展的历程,也对这个领域的优劣势有着清醒的认识。大众也许惊讶于人工智能可以接管现实中很多人类的工作,在天文学领域,人工智能更是一把利器,成为在问题导向下为解决具体天文学科学问题而诞生的新方法、新工具和新算法。本文将就人工智能在21厘米宇宙学领域的科学应用做一简要介绍。
引言
人工智能的出现和发展由来已久。1997年,IBM公司研制的超级计算机“深蓝”首次在正式比赛中战胜了世界冠军获得者、国际象棋大师卡斯帕罗夫(Garry Kasparov),轰动了全世界,但当时人们认为国际象棋规则下的走法变化不够复杂,人工智能真正走向成熟的标志性事件应是对人类围棋高手的挑战。此后经过近20年的漫长发展,2016年,谷歌旗下的DeepMind公司研制的人工智能围棋软件AlphaGo终于向前世界围棋第一人、韩国名将李世石九段发起挑战。这场人机大战以总比分4 :1落下帷幕,机器第一次在围棋规则下打败人类高手。击败李世石的人工智能围棋软件的版本是AlphaGo Master,其利用的是深度学习算法和蒙特卡洛树搜索算法,并在训练过程中用到了大量专业人类棋手的棋谱和下棋数据。2017年,AlphaGo Master进一步升级为AlphaGo Zero,完全摒弃了人类棋谱,一切从零开始,仅依靠自我对弈产生的数据训练出了世界上最强大的围棋棋艺——AlphaGo Zero对战AlphaGo Master的胜率达到90%。

AlphaGo Master与李世石的人机对决。图片来自谷歌公司
AlphaGo的巨大成功深深震撼了世界,也在科学家心中“种上了草”:如何能够将人工智能的超强能力应用到科学研究中,让机器替代人类做一些事情,甚至解决以前不能解决的科学问题?这就是“AI for Science”的核心理念。
2017年,21厘米宇宙学领域第一个“吃螃蟹”的工作出现了。法国巴黎天文台的天文学家岛袋隼士(Hayato Shimabukuro)博士和贝努瓦·塞梅林(Benoit Semelin)教授通过引入最简单的一类机器学习网络——人工神经网络,实现了通过21厘米功率谱数据精确重构宇宙再电离模型参数。为了理解他们的工作,我们首先需要了解什么是宇宙再电离模型参数、21厘米功率谱以及人工神经网络。
宇宙再电离时代和21厘米宇宙学
在宇宙大爆炸后,随着宇宙不断膨胀,温度慢慢降低,电离态的氢(质子)和电子在宇宙38万年时结合成为中性的氢原子,同时形成了宇宙微波背景辐射。这个时候,星系还没有形成,宇宙进入“黑暗时代”。大概在宇宙1亿年的时候,第一代星系才开始出现,它们发出的星光划过黑暗的宇宙,我们称这一时期为“宇宙黎明”。第一代星系发出的星光中有一部分的能量很高,能够把中性的氢原子重新电离掉,也即把中性氢原子内部的电子给“打”出去,重新形成电离态的氢,这个过程就是宇宙再电离。再电离并不是均匀发生的,这些电离氢首先在第一代星系周围形成一个个泡状结构。随着第一代星系越来越多,这些泡会逐渐膨胀扩张,随后多个电离泡碰到一起发生并合,形成形状不规则的更大的泡。最终大约在宇宙十几亿年的时候,整个宇宙被完全电离,宇宙再电离时代结束。
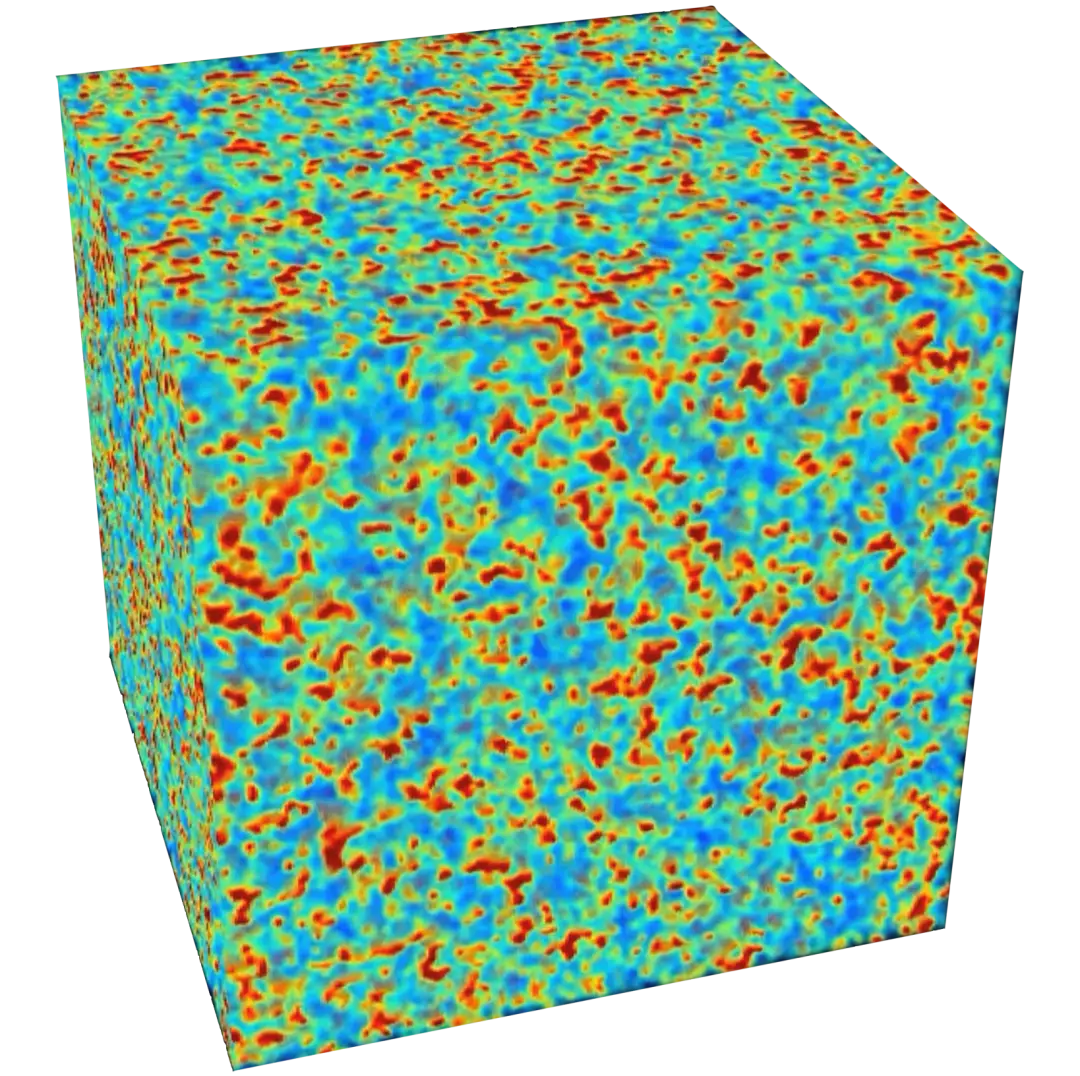
宇宙处于50%的电离阶段的模拟图。图片来自周萌和笔者尚未发表的论文
宇宙再电离是宇宙大爆炸理论的必然推论,但是由于第一代星系的物理性质在观测和理论上都存在巨大的不确定性,直接导致我们目前对宇宙再电离时代,如再电离过程的平均历史、电离泡的成团性等的认识存在很大的不确定空间。对再电离建模的一种做法是引入唯象模型,其中包含若干未知参数。在未来,可通过再电离的观测数据对这些再电离模型参数进行限制,继而对再电离的物理性质进行推断。目前我们对宇宙再电离的观测限制主要来自三种观测探针——宇宙微波背景辐射、莱曼阿尔法森林、莱曼阿尔法发射天体。但是,就像盲人摸象一样,它们只能对再电离的某一项性质进行限制。如果我们想对宇宙再电离时代有一个完整而清晰的理解,那么最佳的观测探针是中性氢21厘米谱线的强度映射,它就像对大象做全身CT扫描一样,可以对处于再电离时代的宇宙做层析照相。
在中性氢内部,有一个电子围绕氢原子核(质子)旋转,电子的自旋和质子的自旋之间有微弱的相互作用。如果电子的自旋方向发生了反转,在这个过程中氢原子会发出一个波长21厘米、频率1.4吉赫兹的微弱光子。在氢原子的光谱中,这条谱线被称为“21厘米谱线”。由于氢是宇宙中丰度最大的元素,从宇宙黑暗时代、宇宙黎明、宇宙再电离时代到近邻宇宙,都充斥着氢,因此21厘米谱线也是射电波段最显著的谱线。这条谱线在不同历史时期发射后,在漫长的传播过程中经历了不同程度的宇宙学红移,因此在今天观测到的频谱中就体现为不同的观测频率。我们可以通过在不同观测频率处、不同天空极坐标上得到的21厘米谱线强度重构出在不同历史时期、不同三维位置上的中性氢气体的物理性质,如物质密度、中性度、温度等,由此得名21厘米层析照相。

通过21厘米谱线强度展示宇宙在某个方向上的演化(基于模拟数据)。图片来自ZHAO X, MAO Y, CHENG C, WANDELT B D. Simulation-Based Inference of Reionization Parameters from 3D Tomographic 21cm Light-cone Images [J]. The Astrophysical Journal, 2022, 926(2): 151
通过面向21厘米谱线的强度测量,我们至少可以提取三种物理量信息。一种是各个方向平均后的全天温度频谱,这可以用小型的单口径天线测得,但缺点是空间分辨率很低,即不知道光是从哪个方向来的。如果想提高望远镜的空间分辨率,就需要扩大射电望远镜的口径,但单口径天线的大小是有极限的。目前世界上最大的单口径射电望远镜是我国的“天眼”(FAST),正如它的全称“500米口径球面射电望远镜”所示,它的口径是500米。
如果要进一步扩大口径,人们想到的办法是让多个天线两两干涉,形成射电干涉阵列,从而提高空间分辨率。当然,这种射电干涉的做法并没有提升望远镜的灵敏度,因为灵敏度是由望远镜接收到的光子数量决定的,而后者由望远镜的接收面积所决定。第一代面向再电离时代的射电干涉阵列,包括位于我国新疆的21厘米阵列(21CMA),它们的灵敏度都不高,不能实现21厘米层析术的图像数据测量。这些实验最直接的科学目标就是测量21厘米谱线强度的统计起伏,更准确地说,是它在傅立叶空间分布的两点关联函数,术语叫作“21厘米功率谱”。这是面向21厘米谱线强度测量的第二种物理量。

平方公里阵列(SKA)。图片来自SKAO
正在建设中的第二代面向再电离时代的射电干涉阵列有两个,一个是中国作为创始成员国参与的国际大科学工程——平方公里阵列射电望远镜(SKA),另一个是美国主导的氢再电离纪元阵列望远镜(HERA)。HERA的科学目标是测量来自宇宙再电离时代的21厘米谱线强度功率谱,而SKA的目标除了测量功率谱,还有实现更高的灵敏度,从而对再电离时代的宇宙进行21厘米层析照相。层析照相是面向21厘米谱线强度测量的第三种物理量,也是最终的目标。
第一个“吃螃蟹”的工作
让我们回到第一个将机器学习应用到21厘米宇宙学的工作,即岛袋隼士博士和塞梅林教授2017年的工作(以下简写作“岛袋—塞梅林2017年的工作”)。在这项工作里,作者在假设未来已测得21厘米谱线功率谱的情况下,通过人工神经网络,解决从功率谱对宇宙再电离模型参数进行精确重构的问题。
什么是人工神经网络?依照芬兰计算机科学家托伊沃·科霍宁(Teuvo Kohonen)给出的定义:“人工神经网络是一种由具有自适应性的简单单元构成的广泛并行互联的网络,它的组织结构能够模拟生物神经系统对真实世界所做出的交互反应。”人工神经网络由一个输入层、一个或多个隐藏层和一个输出层组成,其中输入层从外部源(数据文件、图像等)接收一个数据组,输出层提供一个实现网络功能的数据组。为什么人工神经网络在得到一个训练集之后,能够拥有强大的学习能力呢?奥秘就在隐藏层里。一个典型的人工神经网络包含若干隐藏层,每个隐藏层由若干人工神经元组成,每个神经元接收来自上一个隐藏层的神经元的输入,将它们乘以分配的权重后相加,然后将总和传递给下一个隐藏层的一个或多个神经元。人工神经网络提取输入层数据的各种特征,并将其用不同网络节点连接起来,通过不断改变连接的网络权重,将网络得到的输出层数据与训练集已知(“正确”)的输出层数据相比较,直到网络得到的输出层数据最接近“正确”的答案,这就是训练网络(或者说“学习”)的过程。
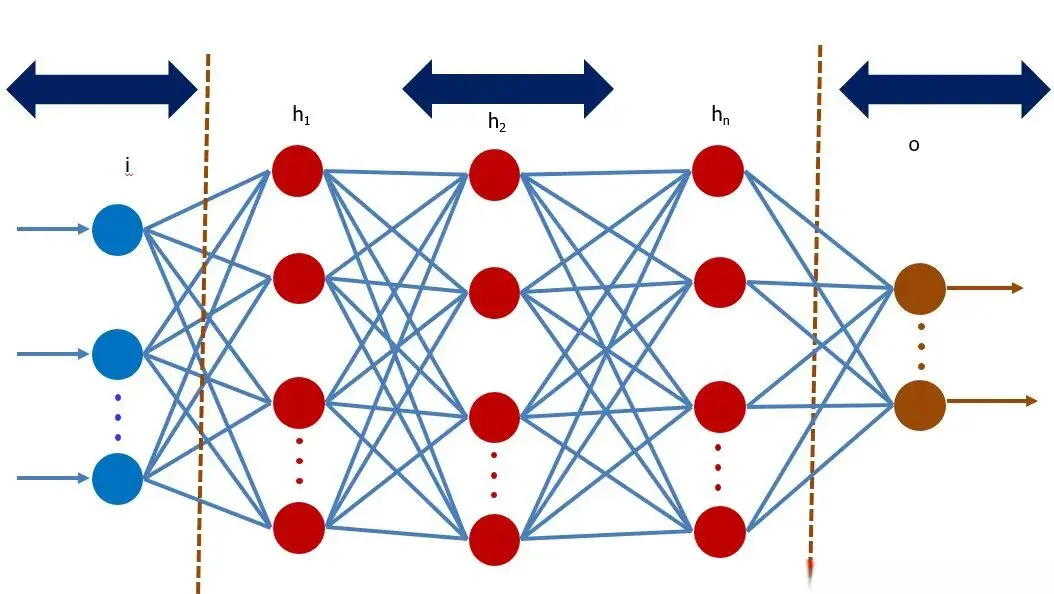
人工神经网络的架构。图片来自wikitechy
在岛袋 — 塞梅林 2017 年的工作里,输入层是 21 厘米功率谱数据(共 14 个处于不同波数的值),输出层是宇宙再电离模型参数数据(共 3 个),隐藏层只采用了一层(共 14 个神经元)。通过这样一个极其简单的人工神经网络架构,作者实现了对宇宙再电离模型参数的高精度重构。
作为第一个在21厘米宇宙学里“吃螃蟹”的工作,岛袋—塞梅林2017年的论文取得了巨大的成功。这一工作从概念上表明机器学习可以极大地简化21厘米功率谱数据的处理,但是它存在一个致命缺陷,使它与实际应用还隔着一条鸿沟。这个缺陷就是他们的工作只能找到最“正确”的输出层数据,但是无法对输出层数据的统计误差做后验推断(即贝叶斯推断);换句话说,他们的工作只能在参数空间里找到拟合最“好”的点(所谓的“点估计”),但是不能告诉我们这个最“好”的点有多“好”。众所周知,统计误差估计是数据分析里最重要的部分,夸张一点地说,抛开误差谈拟合都是不科学的。那么,我们应该如何解决这个重要的问题呢?
第一个“吃龙虾”的工作
笔者在清华大学的团队长期从事宇宙再电离时代和21厘米宇宙学的研究,自从注意到岛袋—塞梅林2017年的工作,我们的研究就开始进入机器学习的科学应用领域。初期,我们曾尝试将三维卷积神经网络应用到21厘米图像数据的压缩过程,从而实现从21厘米层析图像对宇宙再电离模型参数进行重构,这也是对岛袋—塞梅林2017年的工作的推广。然而,笔者很快意识到上文提到的“点估计”缺陷,并开始进入机器学习的不确定性量化分析领域,最终在2019年暑期访问法国巴黎天体物理研究所时,与本杰明·万德尔特(Benjamin Wandelt)教授合作,将无似然推断(likelihood-free inference)引入21厘米宇宙学。笔者团队2022年发表的一篇论文首次在21厘米宇宙学上实现对机器学习提取的物理量进行统计误差的贝叶斯推断,解决了上述问题。这个新方法目前已成为21厘米宇宙学贝叶斯推断的标准做法。因此,相对于第一个“吃螃蟹”的工作,笔者戏称这一工作是第一个“吃龙虾”的工作。
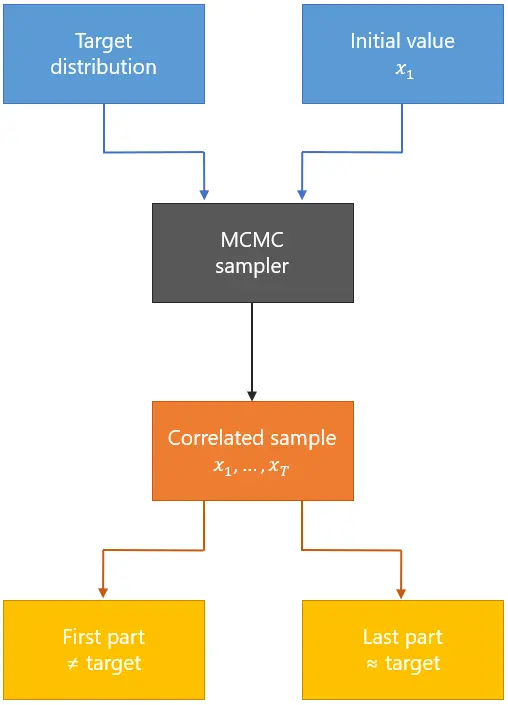
马尔可夫链蒙特卡洛方法是一组用马氏链从随机分布取样的算法,图为MCMC 的方法流程。图片来自StatLect
下面简单介绍一下无似然推断的基本思想。在传统的马尔可夫链蒙特卡罗算法(MCMC)里,贝叶斯推断需要假设似然函数的具体函数形式,一般为高斯函数。无似然推断摒弃了这一假设,具体来说,通过正则流的技术,即一系列非线性变换,将一个原来非高斯分布的参数空间分解并映射到一系列高斯分布的参数空间,从而将非高斯形式的似然函数写为一系列高斯形式的似然函数乘以分配的权重后求和,而每个高斯分布的均值、权重和协方差的数值可以通过训练集数据进行训练得到。因此无似然推断仍然需要计算似然函数,可以理解为它对似然函数的计算是通过训练集数据训练出的似然函数数值大小,只是不再需要对似然函数的具体函数形式做假设,是这个意义上的“无似然”。
结语与展望
本文仅展示了机器学习的一个具体科学应用方向,即参数推断,其本质上属于模式识别。机器学习在21厘米宇宙学领域还有很多其他方向的应用,比如模型分类、物理量和图像的模拟器(emulator)、射电前景扣除等。囿于篇幅,这里不一一展开。这些都是基于监督式学习的算法,并且已经获得广泛应用。然而,由于所有基于监督式学习的算法本质上都依赖于具体模型,不管这种模型是再电离模型、前景模型、噪声模型还是仪器系统响应模型,它们对于再电离21厘米观测都带有不准确性。因此,笔者最后想指出的是,虽然基于非监督式学习的算法,由于自身尚未成熟,目前还没有得到重视,但是人工智能及其科学应用更广阔的前景可能正在于这类算法的开发,它将会带来革命性的范式颠覆,产生更深远的影响。
扬帆配资提示:文章来自网络,不代表本站观点。